strange graph behavior - random machines & graphs
list Gary Baluha
I have recently noticed a strange thing happening with some of the rrd graphs generated by Hobbit. When you look at the graph, it looks as though the rrd data is one one format (gauge), but the graph is generating it in a different format (derive). I can't seem to find any pattern to the hosts or tests that are exhibiting this strange behavior, and it is only happening on a handful of graphs. I have attached a picture of one of these graphs, since I'm not really sure how to describe it. Note the huge numbers displayed on the curr/min/avg/max line. Any idea what's going on here? When I dump the RRD file manually, everything looks okay. I'm running Hobbit 4.2.0 with the 2007-02-09 allinone patch (I believe the latest). This has only happened in the past few weeks, though when exactly it started, I don't know. Any ideas?
list Gary Baluha
Actually, it looks like this is affecting more hosts than I originally thought.
▸
On Nov 28, 2007 10:08 AM, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:
I have recently noticed a strange thing happening with some of the rrd graphs generated by Hobbit. When you look at the graph, it looks as though the rrd data is one one format (gauge), but the graph is generating it in a different format (derive). I can't seem to find any pattern to the hosts or tests that are exhibiting this strange behavior, and it is only happening on a handful of graphs. I have attached a picture of one of these graphs, since I'm not really sure how to describe it. Note the huge numbers displayed on the curr/min/avg/max line. Any idea what's going on here? When I dump the RRD file manually, everything looks okay. I'm running Hobbit 4.2.0 with the 2007-02-09 allinone patch (I believe the latest). This has only happened in the past few weeks, though when exactly it started, I don't know. Any ideas?
list Gary Baluha
Hmm, I just noticed that two completely separate Hobbit servers are having the exact same problem. Again, there is no pattern to which graphs are having this problem, and which ones are not. I even upgraded to the latest version of rrdtool (from 1.2.23 to 1.2.26) and that didn't seem to help.
▸
On Nov 28, 2007 5:39 PM, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:
Actually, it looks like this is affecting more hosts than I originally thought. On Nov 28, 2007 10:08 AM, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:I have recently noticed a strange thing happening with some of the rrd graphs generated by Hobbit. When you look at the graph, it looks as though the rrd data is one one format (gauge), but the graph is generating it in a different format (derive). I can't seem to find any pattern to the hosts or tests that are exhibiting this strange behavior, and it is only happening on a handful of graphs. I have attached a picture of one of these graphs, since I'm not really sure how to describe it. Note the huge numbers displayed on the curr/min/avg/max line. Any idea what's going on here? When I dump the RRD file manually, everything looks okay. I'm running Hobbit 4.2.0 with the 2007-02-09 allinone patch (I believe the latest). This has only happened in the past few weeks, though when exactly it started, I don't know. Any ideas?
list Josh Luthman
This is completely beyond my knowledge, but the first place I would look at is any hardware problems, any recent changes (obviously =) and the similarities between those two Hobbit servers issues.
▸
On 11/29/07, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:Hmm, I just noticed that two completely separate Hobbit servers are having the exact same problem. Again, there is no pattern to which graphs are having this problem, and which ones are not. I even upgraded to the latest version of rrdtool (from 1.2.23 to 1.2.26) and that didn't seem to help. On Nov 28, 2007 5:39 PM, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:Actually, it looks like this is affecting more hosts than I originally thought. On Nov 28, 2007 10:08 AM, Gary Baluha < user-ae3e15c22de1@xymon.invalid> wrote:I have recently noticed a strange thing happening with some of the rrd graphs generated by Hobbit. When you look at the graph, it looks as though the rrd data is one one format (gauge), but the graph is generating it in a different format (derive). I can't seem to find any pattern to the hosts or tests that are exhibiting this strange behavior, and it is only happening on a handful of graphs. I have attached a picture of one of these graphs, since I'm not really sure how to describe it. Note the huge numbers displayed on the curr/min/avg/max line. Any idea what's going on here? When I dump the RRD file manually, everything looks okay. I'm running Hobbit 4.2.0 with the 2007-02-09 allinone patch (I believe the latest). This has only happened in the past few weeks, though when exactly it started, I don't know. Any ideas?
--
Josh Luthman
Office: XXX-XXX-XXXX
Direct: XXX-XXX-XXXX
XXXX Wayne St
Suite XXXX
Troy, OH XXXXX
Those who don't understand UNIX are condemned to reinvent it, poorly.
--- Henry Spencer
list Gary Baluha
▸
On Nov 29, 2007 12:01 PM, Josh Luthman <user-4c45a83f15cb@xymon.invalid> wrote:
This is completely beyond my knowledge, but the first place I would look at is any hardware problems, any recent changes (obviously =) and the similarities between those two Hobbit servers issues.
That's the thing, there aren't any similarities between these two machines. They are different hardware, different OS, different network segment, and different hosts being monitored. There were some recent changes in the past month to one of the hobbit servers, with a bunch of custom RRD graphs added. But this wasn't done on the other hobbit server. The only thing changed on the other hobbit server is more html web checks added; nothing out of the ordinary.
list Josh Luthman
Is this problem not showing up on another Hobbit server? Do the two Hobbit servers with this problem communicate at all (share data/SNMP traffic/etc)?
▸
On 11/29/07, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:On Nov 29, 2007 12:01 PM, Josh Luthman <user-4c45a83f15cb@xymon.invalid> wrote:This is completely beyond my knowledge, but the first place I would look at is any hardware problems, any recent changes (obviously =) and the similarities between those two Hobbit servers issues.That's the thing, there aren't any similarities between these two machines. They are different hardware, different OS, different network segment, and different hosts being monitored. There were some recent changes in the past month to one of the hobbit servers, with a bunch of custom RRD graphs added. But this wasn't done on the other hobbit server. The only thing changed on the other hobbit server is more html web checks added; nothing out of the ordinary.
-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer
list Gary Baluha
We only have two Hobbit servers, and it is affecting both machines. No, these two Hobbit machines do _not_ communicate with each other in any way.
▸
On Nov 29, 2007 2:33 PM, Josh Luthman <user-4c45a83f15cb@xymon.invalid> wrote:
Is this problem not showing up on another Hobbit server? Do the two Hobbit servers with this problem communicate at all (share data/SNMP traffic/etc)? On 11/29/07, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:On Nov 29, 2007 12:01 PM, Josh Luthman <user-4c45a83f15cb@xymon.invalid> wrote:This is completely beyond my knowledge, but the first place I would look at is any hardware problems, any recent changes (obviously =) and the similarities between those two Hobbit servers issues.That's the thing, there aren't any similarities between these two machines. They are different hardware, different OS, different network segment, and different hosts being monitored. There were some recent changes in the past month to one of the hobbit servers, with a bunch of custom RRD graphs added. But this wasn't done on the other hobbit server. The only thing changed on the other hobbit server is more html web checks added; nothing out of the ordinary.-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer
list Gary Baluha
Actually, that's not entirely true. The Hobbit server I run at home, which is obviously in no way at all related, is _not_ having this problem. It does have in common the same version of Hobbit and rrdtool, however.
▸
On Nov 29, 2007 2:37 PM, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:
We only have two Hobbit servers, and it is affecting both machines. No, these two Hobbit machines do _not_ communicate with each other in any way. On Nov 29, 2007 2:33 PM, Josh Luthman < user-4c45a83f15cb@xymon.invalid> wrote:Is this problem not showing up on another Hobbit server? Do the two Hobbit servers with this problem communicate at all (share data/SNMP traffic/etc)? On 11/29/07, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:On Nov 29, 2007 12:01 PM, Josh Luthman <user-4c45a83f15cb@xymon.invalid> wrote:This is completely beyond my knowledge, but the first place I would look at is any hardware problems, any recent changes (obviously =) and the similarities between those two Hobbit servers issues.That's the thing, there aren't any similarities between these two machines. They are different hardware, different OS, different network segment, and different hosts being monitored. There were some recent changes in the past month to one of the hobbit servers, with a bunch of custom RRD graphs added. But this wasn't done on the other hobbit server. The only thing changed on the other hobbit server is more html web checks added; nothing out of the ordinary.-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer
list Josh Luthman
Do they monitor the same devices? I think there has to be some similarity between the two as they had the same problem at the same time (though this isn't 100%, it's logically the first place to look). Hardware isn't of much concern here as they don't communicate and the chances of both servers going bad on the same date is simply astronomical. Are there any kind of auto updating services running on them?
▸
On 11/29/07, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:We only have two Hobbit servers, and it is affecting both machines. No, these two Hobbit machines do _not_ communicate with each other in any way. On Nov 29, 2007 2:33 PM, Josh Luthman < user-4c45a83f15cb@xymon.invalid> wrote:Is this problem not showing up on another Hobbit server? Do the two Hobbit servers with this problem communicate at all (share data/SNMP traffic/etc)? On 11/29/07, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:On Nov 29, 2007 12:01 PM, Josh Luthman <user-4c45a83f15cb@xymon.invalid> wrote:This is completely beyond my knowledge, but the first place I would look at is any hardware problems, any recent changes (obviously =) and the similarities between those two Hobbit servers issues.That's the thing, there aren't any similarities between these two machines. They are different hardware, different OS, different network segment, and different hosts being monitored. There were some recent changes in the past month to one of the hobbit servers, with a bunch of custom RRD graphs added. But this wasn't done on the other hobbit server. The only thing changed on the other hobbit server is more html web checks added; nothing out of the ordinary.-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer
-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer
list Josh Luthman
Same OS at home? Not sure if you mentioned this or not but does that weird value show up in all RRD graphs or just a few hosts?
▸
On 11/29/07, Josh Luthman <user-4c45a83f15cb@xymon.invalid> wrote:Do they monitor the same devices? I think there has to be some similarity between the two as they had the same problem at the same time (though this isn't 100%, it's logically the first place to look). Hardware isn't of much concern here as they don't communicate and the chances of both servers going bad on the same date is simply astronomical. Are there any kind of auto updating services running on them? On 11/29/07, Gary Baluha <user-ae3e15c22de1@xymon.invalid > wrote:We only have two Hobbit servers, and it is affecting both machines. No, these two Hobbit machines do _not_ communicate with each other in any way. On Nov 29, 2007 2:33 PM, Josh Luthman < user-4c45a83f15cb@xymon.invalid> wrote:Is this problem not showing up on another Hobbit server? Do the two Hobbit servers with this problem communicate at all (share data/SNMP traffic/etc)? On 11/29/07, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:On Nov 29, 2007 12:01 PM, Josh Luthman <user-4c45a83f15cb@xymon.invalid> wrote:This is completely beyond my knowledge, but the first place I would look at is any hardware problems, any recent changes (obviously =) and the similarities between those two Hobbit servers issues.That's the thing, there aren't any similarities between these two machines. They are different hardware, different OS, different network segment, and different hosts being monitored. There were some recent changes in the past month to one of the hobbit servers, with a bunch of custom RRD graphs added. But this wasn't done on the other hobbit server. The only thing changed on the other hobbit server is more html web checks added; nothing out of the ordinary.-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer
-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer
list Gary Baluha
They have nothing whatsoever in common. There are no updating services either.
▸
On Nov 29, 2007 2:53 PM, Josh Luthman <user-4c45a83f15cb@xymon.invalid> wrote:
Do they monitor the same devices? I think there has to be some similarity between the two as they had the same problem at the same time (though this isn't 100%, it's logically the first place to look). Hardware isn't of much concern here as they don't communicate and the chances of both servers going bad on the same date is simply astronomical. Are there any kind of auto updating services running on them? On 11/29/07, Gary Baluha <user-ae3e15c22de1@xymon.invalid > wrote:We only have two Hobbit servers, and it is affecting both machines. No, these two Hobbit machines do _not_ communicate with each other in any way. On Nov 29, 2007 2:33 PM, Josh Luthman < user-4c45a83f15cb@xymon.invalid> wrote:Is this problem not showing up on another Hobbit server? Do the two Hobbit servers with this problem communicate at all (share data/SNMP traffic/etc)? On 11/29/07, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:On Nov 29, 2007 12:01 PM, Josh Luthman <user-4c45a83f15cb@xymon.invalid> wrote:This is completely beyond my knowledge, but the first place I would look at is any hardware problems, any recent changes (obviously =) and the similarities between those two Hobbit servers issues.That's the thing, there aren't any similarities between these two machines. They are different hardware, different OS, different network segment, and different hosts being monitored. There were some recent changes in the past month to one of the hobbit servers, with a bunch of custom RRD graphs added. But this wasn't done on the other hobbit server. The only thing changed on the other hobbit server is more html web checks added; nothing out of the ordinary.-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer
list Gary Baluha
I don't know how many hosts are affected, percentage wise, but it's definitely not every host. And for the hosts having the problem, it's not even the same graphs that are having the problem.
▸
On Nov 29, 2007 3:11 PM, Josh Luthman <user-4c45a83f15cb@xymon.invalid> wrote:
Same OS at home? Not sure if you mentioned this or not but does that weird value show up in all RRD graphs or just a few hosts? On 11/29/07, Josh Luthman <user-4c45a83f15cb@xymon.invalid> wrote:Do they monitor the same devices? I think there has to be some similarity between the two as they had the same problem at the same time (though this isn't 100%, it's logically the first place to look). Hardware isn't of much concern here as they don't communicate and the chances of both servers going bad on the same date is simply astronomical. Are there any kind of auto updating services running on them? On 11/29/07, Gary Baluha < user-ae3e15c22de1@xymon.invalid > wrote:We only have two Hobbit servers, and it is affecting both machines. No, these two Hobbit machines do _not_ communicate with each other in any way. On Nov 29, 2007 2:33 PM, Josh Luthman < user-4c45a83f15cb@xymon.invalid> wrote:Is this problem not showing up on another Hobbit server? Do the two Hobbit servers with this problem communicate at all (share data/SNMP traffic/etc)? On 11/29/07, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:On Nov 29, 2007 12:01 PM, Josh Luthman < user-4c45a83f15cb@xymon.invalid> wrote:This is completely beyond my knowledge, but the first place I would look at is any hardware problems, any recent changes (obviously =) and the similarities between those two Hobbit servers issues.That's the thing, there aren't any similarities between these two machines. They are different hardware, different OS, different network segment, and different hosts being monitored. There were some recent changes in the past month to one of the hobbit servers, with a bunch of custom RRD graphs added. But this wasn't done on the other hobbit server. The only thing changed on the other hobbit server is more html web checks added; nothing out of the ordinary.-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer
list Josh Luthman
Can you do a dd if=/dev/sda of=/dev/null from the disk in which the stuff is stored? If it is so random I'm curious to see if the fs is having problems. I have my money on a bug in the software or bad disk/fs/controller.
▸
On 11/29/07, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:I don't know how many hosts are affected, percentage wise, but it's definitely not every host. And for the hosts having the problem, it's not even the same graphs that are having the problem. On Nov 29, 2007 3:11 PM, Josh Luthman <user-4c45a83f15cb@xymon.invalid> wrote:Same OS at home? Not sure if you mentioned this or not but does that weird value show up in all RRD graphs or just a few hosts? On 11/29/07, Josh Luthman <user-4c45a83f15cb@xymon.invalid> wrote:Do they monitor the same devices? I think there has to be some similarity between the two as they had the same problem at the same time (though this isn't 100%, it's logically the first place to look). Hardware isn't of much concern here as they don't communicate and the chances of both servers going bad on the same date is simply astronomical. Are there any kind of auto updating services running on them? On 11/29/07, Gary Baluha < user-ae3e15c22de1@xymon.invalid > wrote:We only have two Hobbit servers, and it is affecting both machines. No, these two Hobbit machines do _not_ communicate with each other in any way. On Nov 29, 2007 2:33 PM, Josh Luthman < user-4c45a83f15cb@xymon.invalid> wrote:Is this problem not showing up on another Hobbit server? Do the two Hobbit servers with this problem communicate at all (share data/SNMP traffic/etc)? On 11/29/07, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:On Nov 29, 2007 12:01 PM, Josh Luthman < user-4c45a83f15cb@xymon.invalid> wrote:This is completely beyond my knowledge, but the first place I would look at is any hardware problems, any recent changes (obviously =) and the similarities between those two Hobbit servers issues.That's the thing, there aren't any similarities between these two machines. They are different hardware, different OS, different network segment, and different hosts being monitored. There were some recent changes in the past month to one of the hobbit servers, with a bunch of custom RRD graphs added. But this wasn't done on the other hobbit server. The only thing changed on the other hobbit server is more html web checks added; nothing out of the ordinary.-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer
-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer
list Gary Baluha
Unfortunately, no, I can't do this as our Hobbit server monitors production machines. The data directory for the rrd files are SAN-mounted, and we haven't had disk corruption issues before with this type of setup. The strange thing is, this only started within the past week, and unfortunately it seems to be spreading to more and more RRD graphs.
▸
On Nov 29, 2007 3:41 PM, Josh Luthman <user-4c45a83f15cb@xymon.invalid> wrote:
Can you do a dd if=/dev/sda of=/dev/null from the disk in which the stuff is stored? If it is so random I'm curious to see if the fs is having problems. I have my money on a bug in the software or bad disk/fs/controller. On 11/29/07, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:I don't know how many hosts are affected, percentage wise, but it's definitely not every host. And for the hosts having the problem, it's not even the same graphs that are having the problem. On Nov 29, 2007 3:11 PM, Josh Luthman <user-4c45a83f15cb@xymon.invalid> wrote:Same OS at home? Not sure if you mentioned this or not but does that weird value show up in all RRD graphs or just a few hosts? On 11/29/07, Josh Luthman <user-4c45a83f15cb@xymon.invalid> wrote:Do they monitor the same devices? I think there has to be some similarity between the two as they had the same problem at the same time (though this isn't 100%, it's logically the first place to look). Hardware isn't of much concern here as they don't communicate and the chances of both servers going bad on the same date is simply astronomical. Are there any kind of auto updating services running on them? On 11/29/07, Gary Baluha < user-ae3e15c22de1@xymon.invalid > wrote:We only have two Hobbit servers, and it is affecting both machines. No, these two Hobbit machines do _not_ communicate with each other in any way. On Nov 29, 2007 2:33 PM, Josh Luthman < user-4c45a83f15cb@xymon.invalid> wrote:Is this problem not showing up on another Hobbit server? Do the two Hobbit servers with this problem communicate at all (share data/SNMP traffic/etc)? On 11/29/07, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:On Nov 29, 2007 12:01 PM, Josh Luthman < user-4c45a83f15cb@xymon.invalid> wrote:This is completely beyond my knowledge, but the first place I would look at is any hardware problems, any recent changes (obviously =) and the similarities between those two Hobbit servers issues.That's the thing, there aren't any similarities between these two machines. They are different hardware, different OS, different network segment, and different hosts being monitored. There were some recent changes in the past month to one of the hobbit servers, with a bunch of custom RRD graphs added. But this wasn't done on the other hobbit server. The only thing changed on the other hobbit server is more html web checks added; nothing out of the ordinary.-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer
list Gary Baluha
Some additional information... If I delete the RRD files that become corrupted like this and let them rebuild, not only does it rebuild it corrupted again, but if you click on the graph for the full history, all four of the historical graphs show the exact same corrupted data. That is, it has a full 576 days worth of corrupted, invalid data, even though the RRD file has only had data going to it for a handful of Hobbit polling cycles.
list Josh Luthman
Is it possible that hosts are getting combined?
▸
On 11/29/07, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:Some additional information... If I delete the RRD files that become corrupted like this and let them rebuild, not only does it rebuild it corrupted again, but if you click on the graph for the full history, all four of the historical graphs show the exact same corrupted data. That is, it has a full 576 days worth of corrupted, invalid data, even though the RRD file has only had data going to it for a handful of Hobbit polling cycles.
-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer
list Greg L Hubbard
Sounds like your SAN is needs some love. From: Gary Baluha [mailto:user-ae3e15c22de1@xymon.invalid] Sent: Thursday, November 29, 2007 3:26 PM To: user-ae9b8668bcde@xymon.invalid Subject: Re: [hobbit] strange graph behavior - random machines & graphs
▸
Some additional information... If I delete the RRD files that
become corrupted like this and let them rebuild, not only does it
rebuild it corrupted again, but if you click on the graph for the full
history, all four of the historical graphs show the exact same corrupted
data. That is, it has a full 576 days worth of corrupted, invalid data,
even though the RRD file has only had data going to it for a handful of
Hobbit polling cycles.
list Josh Luthman
Is Hobbit the only thing running on your SAN? Have you had any other issues with it by chance? You can ship it to my house for extensive testing if needed.
▸
On 11/29/07, Hubbard, Greg L <user-d970b5e56ec9@xymon.invalid> wrote:Sounds like your SAN is needs some love. *From:* Gary Baluha [mailto:user-ae3e15c22de1@xymon.invalid] *Sent:* Thursday, November 29, 2007 3:26 PM *To:* user-ae9b8668bcde@xymon.invalid *Subject:* Re: [hobbit] strange graph behavior - random machines & graphs Some additional information... If I delete the RRD files that become corrupted like this and let them rebuild, not only does it rebuild it corrupted again, but if you click on the graph for the full history, all four of the historical graphs show the exact same corrupted data. That is, it has a full 576 days worth of corrupted, invalid data, even though the RRD file has only had data going to it for a handful of Hobbit polling cycles.
-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer
list Gary Baluha
Now this appears it is becoming a more serious problem. It seems more and more graphs are starting to be affected, and I still have no explanation for what is going on here. It also seems that almost any new graph that is created (such as if I delete/rename/move an existing .rrd file), it immediately starts off being corrupted. :-(
▸
On Nov 28, 2007 10:08 AM, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:
I have recently noticed a strange thing happening with some of the rrd graphs generated by Hobbit. When you look at the graph, it looks as though the rrd data is one one format (gauge), but the graph is generating it in a different format (derive). I can't seem to find any pattern to the hosts or tests that are exhibiting this strange behavior, and it is only happening on a handful of graphs. I have attached a picture of one of these graphs, since I'm not really sure how to describe it. Note the huge numbers displayed on the curr/min/avg/max line. Any idea what's going on here? When I dump the RRD file manually, everything looks okay. I'm running Hobbit 4.2.0 with the 2007-02-09 allinone patch (I believe the latest). This has only happened in the past few weeks, though when exactly it started, I don't know. Any ideas?
list Josh Luthman
Like I said before, I don't know enough to really help you and I'm shooting in the dark to try and help! I would try to get a whole new box together and try to replicate it. Install the same OS/software and copy the whole ~hobbit and see if it starts up there.
▸
On 11/30/07, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:Now this appears it is becoming a more serious problem. It seems more and more graphs are starting to be affected, and I still have no explanation for what is going on here. It also seems that almost any new graph that is created (such as if I delete/rename/move an existing .rrd file), it immediately starts off being corrupted. :-( On Nov 28, 2007 10:08 AM, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:I have recently noticed a strange thing happening with some of the rrd graphs generated by Hobbit. When you look at the graph, it looks as though the rrd data is one one format (gauge), but the graph is generating it in a different format (derive). I can't seem to find any pattern to the hosts or tests that are exhibiting this strange behavior, and it is only happening on a handful of graphs. I have attached a picture of one of these graphs, since I'm not really sure how to describe it. Note the huge numbers displayed on the curr/min/avg/max line. Any idea what's going on here? When I dump the RRD file manually, everything looks okay. I'm running Hobbit 4.2.0 with the 2007-02-09 allinone patch (I believe the latest). This has only happened in the past few weeks, though when exactly it started, I don't know. Any ideas?
-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer
list Greg L Hubbard
Gary, This is pretty hard to decipher from "afar". I think I remember you saying that when you dump the data it is always okay? Some wild thoughts: a) could there be two different processes updating the same RRD files? b) are all servers using the same version of rrdtool? c) are the hobbitgraph files okay? I have proven to my satisfaction that hobbitgraph definition errors can make the graphs act funny. d) if this stuff is on a SAN, can it be moved to local storage? I am just "fishing." Sometimes, when I am at my wit's end, I just change SOMETHING to see if it makes a difference. Even WORSE can help get me started. GLH
▸
From: Gary Baluha [mailto:user-ae3e15c22de1@xymon.invalid]
Sent: Friday, November 30, 2007 9:25 AM
To: user-ae9b8668bcde@xymon.invalid
Subject: Re: [hobbit] strange graph behavior - random machines &
graphs
Now this appears it is becoming a more serious problem. It
seems more and more graphs are starting to be affected, and I still have
no explanation for what is going on here. It also seems that almost any
new graph that is created (such as if I delete/rename/move an existing
.rrd file), it immediately starts off being corrupted. :-(
On Nov 28, 2007 10:08 AM, Gary Baluha <user-ae3e15c22de1@xymon.invalid>
wrote:
I have recently noticed a strange thing happening with
some of the rrd graphs generated by Hobbit. When you look at the graph,
it looks as though the rrd data is one one format (gauge), but the graph
is generating it in a different format (derive). I can't seem to find
any pattern to the hosts or tests that are exhibiting this strange
behavior, and it is only happening on a handful of graphs. I have
attached a picture of one of these graphs, since I'm not really sure how
to describe it. Note the huge numbers displayed on the curr/min/avg/max
line.
Any idea what's going on here? When I dump the RRD file
manually, everything looks okay. I'm running Hobbit 4.2.0 with the
2007-02-09 allinone patch (I believe the latest). This has only
happened in the past few weeks, though when exactly it started, I don't
know. Any ideas?
list Gary Baluha
▸
On Nov 30, 2007 10:53 AM, Hubbard, Greg L <user-d970b5e56ec9@xymon.invalid> wrote:
Gary, This is pretty hard to decipher from "afar". I think I remember you saying that when you dump the data it is always okay?
Actually, it turns out this is not true. The rrd file does indeed have the bad data. I just didn't notice it before, but now that it appears to be getting worse, it is quite obvious to see the bad data.
▸
Some wild thoughts:a) could there be two different processes updating the same RRD files?
I don't believe so. The strange thing is, all of the graphs that become corrupted have the exact same large number that is being input into the rrd data files.
b) are all servers using the same version of rrdtool?
No. One is running 1.2.23, the other 1.2.26. Both have the problem.
▸
c) are the hobbitgraph files okay? I have proven to my satisfaction that hobbitgraph definition errors can make the graphs act funny.
They haven't changed since before the graphs were having this problem.
d) if this stuff is on a SAN, can it be moved to local storage?
It is on the SAN on one of the machines, and locally on the other. I was thinking of temporarily moving the data directory and have Hobbit regenerate all the data from scratch. I'm trying to avoid this, since that would mean losing a year's worth of trend data that has proven itself very useful. Still, if it helps me narrow down the problem, I'll consider this (and move the data back once I get my answer).
▸
I am just "fishing." Sometimes, when I am at my wit's end, I just change SOMETHING to see if it makes a difference. Even WORSE can help get me started. GLH *From:* Gary Baluha [mailto:user-ae3e15c22de1@xymon.invalid] *Sent:* Friday, November 30, 2007 9:25 AM *To:* user-ae9b8668bcde@xymon.invalid *Subject:* Re: [hobbit] strange graph behavior - random machines & graphs Now this appears it is becoming a more serious problem. It seems more and more graphs are starting to be affected, and I still have no explanation for what is going on here. It also seems that almost any new graph that is created (such as if I delete/rename/move an existing .rrd file), it immediately starts off being corrupted. :-( On Nov 28, 2007 10:08 AM, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:I have recently noticed a strange thing happening with some of the rrd graphs generated by Hobbit. When you look at the graph, it looks as though the rrd data is one one format (gauge), but the graph is generating it in a different format (derive). I can't seem to find any pattern to the hosts or tests that are exhibiting this strange behavior, and it is only happening on a handful of graphs. I have attached a picture of one of these graphs, since I'm not really sure how to describe it. Note the huge numbers displayed on the curr/min/avg/max line. Any idea what's going on here? When I dump the RRD file manually, everything looks okay. I'm running Hobbit 4.2.0 with the 2007-02-09 allinone patch (I believe the latest). This has only happened in the past few weeks, though when exactly it started, I don't know. Any ideas?
list Gary Baluha
Hmm, this is getting curiouser and curiouser. Apparently at least _some_ of the graphs that appear corrupted still have some valid data. If I use the graph zoom feature (clicking on the magnifying glass) and select certain portions of the graph, the graph data shows up as normal. It appears that the problem is related to periodic data artifacts (the huge numbers) that cause the scale of the graph to resize to show it within bounds, and this causes the valid data to essentially disappear. I realized this when I looked at the graph, and saw that the (curr) and (min) data points were showing normal values. It's just the (max) and (avg) values that are way off, which causes the rest of the graph to be incorrect.
list Ralph Mitchell
▸
On Nov 30, 2007 10:55 AM, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:
Hmm, this is getting curiouser and curiouser. Apparently at least _some_ of the graphs that appear corrupted still have some valid data. If I use the graph zoom feature (clicking on the magnifying glass) and select certain portions of the graph, the graph data shows up as normal. It appears that the problem is related to periodic data artifacts (the huge numbers) that cause the scale of the graph to resize to show it within bounds, and this causes the valid data to essentially disappear. I realized this when I looked at the graph, and saw that the (curr) and (min) data points were showing normal values. It's just the (max) and (avg) values that are way off, which causes the rest of the graph to be incorrect.
Have you tried running hobbitd_rrd with the "--debug" option?? Add it to the various hobbitd_rrd entries in server/etc/hobbitlaunch.cfg. I haven't tried it myself, so I don't know how verbose it gets. I seem to recall Henrik saying it's OK to just kill hobbitd_rrd processes because they get respawned. I guess the debug output shows up in the rrd-status.log in your Hobbit logs directory. Is there anything interesting in that log already?? Or any other log?? Ralph Mitchell
list Greg L Hubbard
It sounds like you are zeroing in on the problem. Based on your other post (and this) it seems that the data is getting logged okay in the RRD, and that data is being faithfully reproduced by the graphs. The problem is that the data itself has unexpected values. So whatever is providing that data to the RRD is either faulty, or is in turn being misled by something else further upstream. I don't remember where you said that this data was coming from. I know there can be a problem with "rollovers" when a signed integer is used as a counter and it grows to the point where the sign bit flips. This can cause a big jump in a reading if the software cannot handle the switch from 2,147,483,647 (hex 7FFFFFF) to the next value (hex 80000000) which flips the sign bit for a signed 32 bit integer. This has been a problem in the SNMP world for YEARS. There, I knew some of the computer science 101 stuff I learned in the 70's might be useful some day...
▸
GLH
From: Gary Baluha [mailto:user-ae3e15c22de1@xymon.invalid]
Sent: Friday, November 30, 2007 10:15 AM
To: user-ae9b8668bcde@xymon.invalid
Subject: Re: [hobbit] strange graph behavior - random machines &
graphs
On Nov 30, 2007 10:53 AM, Hubbard, Greg L <user-d970b5e56ec9@xymon.invalid>
wrote:
Gary,
This is pretty hard to decipher from "afar".
I think I remember you saying that when you dump the
data it is always okay?
Actually, it turns out this is not true. The rrd file does
indeed have the bad data. I just didn't notice it before, but now that
it appears to be getting worse, it is quite obvious to see the bad data.
Some wild thoughts:
a) could there be two different processes updating the
same RRD files?
I don't believe so. The strange thing is, all of the graphs
that become corrupted have the exact same large number that is being
input into the rrd data files.
b) are all servers using the same version of rrdtool?
No. One is running 1.2.23, the other 1.2.26. Both have the
problem.
c) are the hobbitgraph files okay? I have proven to my
satisfaction that hobbitgraph definition errors can make the graphs act
funny.
They haven't changed since before the graphs were having this
problem.
d) if this stuff is on a SAN, can it be moved to local
storage?
It is on the SAN on one of the machines, and locally on the
other. I was thinking of temporarily moving the data directory and have
Hobbit regenerate all the data from scratch. I'm trying to avoid this,
since that would mean losing a year's worth of trend data that has
proven itself very useful. Still, if it helps me narrow down the
problem, I'll consider this (and move the data back once I get my
answer).
I am just "fishing." Sometimes, when I am at my wit's
end, I just change SOMETHING to see if it makes a difference. Even WORSE
can help get me started.
GLH
From: Gary Baluha [mailto:user-ae3e15c22de1@xymon.invalid]
Sent: Friday, November 30, 2007 9:25 AM
To: user-ae9b8668bcde@xymon.invalid
Subject: Re: [hobbit] strange graph behavior -
random machines & graphs
Now this appears it is becoming a more serious
problem. It seems more and more graphs are starting to be affected, and
I still have no explanation for what is going on here. It also seems
that almost any new graph that is created (such as if I
delete/rename/move an existing .rrd file), it immediately starts off
being corrupted. :-(
On Nov 28, 2007 10:08 AM, Gary Baluha
<user-ae3e15c22de1@xymon.invalid> wrote:
I have recently noticed a strange thing
happening with some of the rrd graphs generated by Hobbit. When you
look at the graph, it looks as though the rrd data is one one format
(gauge), but the graph is generating it in a different format (derive).
I can't seem to find any pattern to the hosts or tests that are
exhibiting this strange behavior, and it is only happening on a handful
of graphs. I have attached a picture of one of these graphs, since I'm
not really sure how to describe it. Note the huge numbers displayed on
the curr/min/avg/max line.
Any idea what's going on here? When I
dump the RRD file manually, everything looks okay. I'm running Hobbit
4.2.0 with the 2007-02-09 allinone patch (I believe the latest). This
has only happened in the past few weeks, though when exactly it started,
I don't know. Any ideas?
list Gary Baluha
▸
On Nov 30, 2007 12:18 PM, Ralph Mitchell <user-00a5e44c48c0@xymon.invalid> wrote:
On Nov 30, 2007 10:55 AM, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:Hmm, this is getting curiouser and curiouser. Apparently at least _some_ of the graphs that appear corrupted still have some valid data. If I use the graph zoom feature (clicking on the magnifying glass) and select certain portions of the graph, the graph data shows up as normal. It appears that the problem is related to periodic data artifacts (the huge numbers) that cause the scale of the graph to resize to show it within bounds, and this causes the valid data to essentially disappear. I realized this when I looked at the graph, and saw that the (curr) and (min) data points were showing normal values. It's just the (max) and (avg) values that are way off, which causes the rest of the graph to be incorrect.Have you tried running hobbitd_rrd with the "--debug" option?? Add it to the various hobbitd_rrd entries in server/etc/hobbitlaunch.cfg. I haven't tried it myself, so I don't know how verbose it gets. I seem to recall Henrik saying it's OK to just kill hobbitd_rrd processes because they get respawned. I guess the debug output shows up in the rrd-status.log in your Hobbit logs directory. Is there anything interesting in that log already?? Or any other log??
There wasn't anything useful in any of the logs, besides the usual stuff. I
turned on the --debug option, and here is a sample of the data for one of
the affected machines:
2007-11-30 13:14:07 hobbitd_rrd: Got message 562165
@@status#562165|1196446447.724393|192.168.232.110||danno|disk|1196448247|yellow||yellow|1196053505|0||0||1196446447
2007-11-30 13:14:07 startpos 343968, fillpos 343968, endpos -1
2007-11-30 13:14:07 RRD update param 00: 'rrdupdate'
2007-11-30 13:14:07 RRD update param 01:
'/var/hobbit/data/rrd/danno/disk,dev,odm.rrd'
2007-11-30 13:14:07 RRD update param 02: '-t'
2007-11-30 13:14:07 RRD update param 03: 'pct:used'
2007-11-30 13:14:07 RRD update param 04: '1196446447:0:0'
I'm afraid I don't know how to interpret all of this, unfortunately. I get
that the "param 03" means the graph is showing "percentage [disk space]
used", and that "param 01" means it is updating that specific rrd file. And
I remember that "-t" in "param 02" is some rrdtool flag. But I don't know
what the numbers in "param 04" mean. I assume the first number is the #
seconds since 1970, and the second number is the current value, but I don't
know what the last number means. Also, I'm not sure how to interpret all of
the data in the "@@status" line.
By the way, this excerpt is from a machine that is having the graph display
problems. In this case, the data it is receiving is normal and correct.
I'm waiting for another update when the data is incorrect.
list Gary Baluha
▸
On Nov 30, 2007 1:15 PM, Hubbard, Greg L <user-d970b5e56ec9@xymon.invalid> wrote:
It sounds like you are zeroing in on the problem. Based on your other post (and this) it seems that the data is getting logged okay in the RRD, and that data is being faithfully reproduced by the graphs. The problem is that the data itself has unexpected values. So whatever is providing that data to the RRD is either faulty, or is in turn being misled by something else further upstream.
Yeah, I'm fairly confident now that it is the initial data being fed into the rrd file that is faulty. I'm still not sure what the initial "entry point" of this bad data is, though, nor why it is happening. I have a feeling that once I determine where the entry point is, that will lead me to the "why".
▸
I don't remember where you said that this data was coming from. I know there can be a problem with "rollovers" when a signed integer is used as a counter and it grows to the point where the sign bit flips. This can cause a big jump in a reading if the software cannot handle the switch from 2,147,483,647 (hex 7FFFFFF) to the next value (hex 80000000) which flips the sign bit for a signed 32 bit integer. This has been a problem in the SNMP world for YEARS.
Hrm, that has been something vaguely on my mind. But I haven't really thought of that as _the_ reason why, since I don't know why there would be some sort of data rollover. We're talking about load average and disk space usage graphs that are showing invalid data. I'm also curious why it would have started all of a sudden, on two separate machines. But it does seem more and more like something like an integer rollover, or similar situation.
list Josh Luthman
This is on the hobbitd incoming messages service being watched, correct (judging by the screen capture)? You said it started happening on two different servers but now it is happening on additional graphs; what data are these new graphs showing?
▸
On 11/30/07, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:On Nov 30, 2007 1:15 PM, Hubbard, Greg L <user-d970b5e56ec9@xymon.invalid> wrote:It sounds like you are zeroing in on the problem. Based on your other post (and this) it seems that the data is getting logged okay in the RRD, and that data is being faithfully reproduced by the graphs. The problem is that the data itself has unexpected values. So whatever is providing that data to the RRD is either faulty, or is in turn being misled by something else further upstream.Yeah, I'm fairly confident now that it is the initial data being fed into the rrd file that is faulty. I'm still not sure what the initial "entry point" of this bad data is, though, nor why it is happening. I have a feeling that once I determine where the entry point is, that will lead me to the "why".I don't remember where you said that this data was coming from. I know there can be a problem with "rollovers" when a signed integer is used as a counter and it grows to the point where the sign bit flips. This can cause a big jump in a reading if the software cannot handle the switch from 2,147,483,647 (hex 7FFFFFF) to the next value (hex 80000000) which flips the sign bit for a signed 32 bit integer. This has been a problem in the SNMP world for YEARS.Hrm, that has been something vaguely on my mind. But I haven't really thought of that as _the_ reason why, since I don't know why there would be some sort of data rollover. We're talking about load average and disk space usage graphs that are showing invalid data. I'm also curious why it would have started all of a sudden, on two separate machines. But it does seem more and more like something like an integer rollover, or similar situation.
-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer
list Ralph Mitchell
▸
On Nov 30, 2007 12:27 PM, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:
There wasn't anything useful in any of the logs, besides the usual stuff. I turned on the --debug option, and here is a sample of the data for one of the affected machines: 2007-11-30 13:14:07 hobbitd_rrd: Got message 562165 @@status#562165|1196446447.724393|192.168.232.110||danno|disk|1196448247|yellow||yellow|1196053505|0||0||1196446447 2007-11-30 13:14:07 startpos 343968, fillpos 343968, endpos -1 2007-11-30 13:14:07 RRD update param 00: 'rrdupdate' 2007-11-30 13:14:07 RRD update param 01: '/var/hobbit/data/rrd/danno/disk,dev,odm.rrd' 2007-11-30 13:14:07 RRD update param 02: '-t' 2007-11-30 13:14:07 RRD update param 03: 'pct:used' 2007-11-30 13:14:07 RRD update param 04: '1196446447:0:0' I'm afraid I don't know how to interpret all of this, unfortunately. I get that the "param 03" means the graph is showing "percentage [disk space] used", and that "param 01" means it is updating that specific rrd file. And I remember that "-t" in "param 02" is some rrdtool flag. But I don't know what the numbers in "param 04" mean. I assume the first number is the # seconds since 1970, and the second number is the current value, but I don't know what the last number means. Also, I'm not sure how to interpret all of the data in the "@@status" line. By the way, this excerpt is from a machine that is having the graph display problems. In this case, the data it is receiving is normal and correct. I'm waiting for another update when the data is incorrect.
The "-t" option specifies the template to use, which is in param03 - "pct:used". Param 04 is the actual data to insert, starting with the date/time in seconds (i.e. 1196446447), then zero for the "pct" value, then zero for the "used" value. This stuff may not help much, but maybe it will show where the data goes weird - i.e. is hobbitd_rrd being handed bad data, or does it get corrupted later on. Ralph Mitchell
list Gary Baluha
▸
On Nov 30, 2007 1:38 PM, Josh Luthman <user-4c45a83f15cb@xymon.invalid> wrote:
This is on the hobbitd incoming messages service being watched, correct (judging by the screen capture)? You said it started happening on two different servers but now it is happening on additional graphs; what data are these new graphs showing?
The log except was from rrd-status.rrd, so from the hobbitd_rrd process. We
have two physically separate Hobbit servers, on two physically different and
non-connected networks. Let's call one of them Hobbit A, and the other
Hobbit B. I first noticed a few graphs on Hobbit A were showing artifacts.
This was happening for a few hosts, and of those hosts, only a few of their
trend graphs, and not always the same trend graphs across the different
hosts. I then noticed that the same thing was happening on Hobbit B. Now
it appears more graphs are being affected on Hobbit A (I don't know about
Hobbit B, as A has the most monitored hosts, and so I'm first concerned with
that machine). Graphs that were previous unaffected are now being
affected. They are all showing the same symptom. That is, spikes of data
with the exact same number:
5177668251... (it's a very big number, at least 50 digits).
list Gary Baluha
▸
On Nov 30, 2007 1:45 PM, Ralph Mitchell <user-00a5e44c48c0@xymon.invalid> wrote:
On Nov 30, 2007 12:27 PM, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:There wasn't anything useful in any of the logs, besides the usual stuff. I turned on the --debug option, and here is a sample of the data for one of the affected machines: 2007-11-30 13:14:07 hobbitd_rrd: Got message 562165 @@status#562165|1196446447.724393|192.168.232.110||danno|disk|1196448247|yellow||yellow|1196053505|0||0||1196446447 2007-11-30 13:14:07 startpos 343968, fillpos 343968, endpos -1 2007-11-30 13:14:07 RRD update param 00: 'rrdupdate' 2007-11-30 13:14:07 RRD update param 01: '/var/hobbit/data/rrd/danno/disk,dev,odm.rrd' 2007-11-30 13:14:07 RRD update param 02: '-t' 2007-11-30 13:14:07 RRD update param 03: 'pct:used' 2007-11-30 13:14:07 RRD update param 04: '1196446447:0:0' I'm afraid I don't know how to interpret all of this, unfortunately. I get that the "param 03" means the graph is showing "percentage [disk space] used", and that "param 01" means it is updating that specific rrd file. And I remember that "-t" in "param 02" is some rrdtool flag. But I don't know what the numbers in "param 04" mean. I assume the first number is the # seconds since 1970, and the second number is the current value, but I don't know what the last number means. Also, I'm not sure how to interpret all of the data in the "@@status" line. By the way, this excerpt is from a machine that is having the graph display problems. In this case, the data it is receiving is normal and correct. I'm waiting for another update when the data is incorrect.The "-t" option specifies the template to use, which is in param03 - "pct:used". Param 04 is the actual data to insert, starting with the date/time in seconds (i.e. 1196446447), then zero for the "pct" value, then zero for the "used" value. This stuff may not help much, but maybe it will show where the data goes weird - i.e. is hobbitd_rrd being handed bad data, or does it get corrupted later on.
That's what I'm hoping. One other thing I noticed is that for the hosts that have bad graphs, but where some graphs are still okay, the good graphs have a gap of data precisely when the bad graphs have another data spike.
list Josh Luthman
Another idea! Since the two networks/Hobbit servers are unrelated theres little in common. What about the time? Maybe some data from one set got mixed in and it doesn't cooperate with the date and time?
▸
On 11/30/07, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:On Nov 30, 2007 1:45 PM, Ralph Mitchell <user-00a5e44c48c0@xymon.invalid> wrote:On Nov 30, 2007 12:27 PM, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:There wasn't anything useful in any of the logs, besides the usual stuff. I turned on the --debug option, and here is a sample of the data for one of the affected machines: 2007-11-30 13:14:07 hobbitd_rrd: Got message 562165 @@status#562165|1196446447.724393|192.168.232.110||danno|disk|1196448247|yellow||yellow|1196053505|0||0||1196446447 2007-11-30 13:14:07 startpos 343968, fillpos 343968, endpos -1 2007-11-30 13:14:07 RRD update param 00: 'rrdupdate' 2007-11-30 13:14:07 RRD update param 01: '/var/hobbit/data/rrd/danno/disk,dev,odm.rrd' 2007-11-30 13:14:07 RRD update param 02: '-t' 2007-11-30 13:14:07 RRD update param 03: 'pct:used' 2007-11-30 13:14:07 RRD update param 04: '1196446447:0:0' I'm afraid I don't know how to interpret all of this, unfortunately. I get that the "param 03" means the graph is showing "percentage [disk space] used", and that "param 01" means it is updating that specific rrd file. And I remember that "-t" in "param 02" is some rrdtool flag. But I don't know what the numbers in "param 04" mean. I assume the first number is the # seconds since 1970, and the second number is the current value, but I don't know what the last number means. Also, I'm not sure how to interpret all of the data in the "@@status" line. By the way, this excerpt is from a machine that is having the graph display problems. In this case, the data it is receiving is normal and correct. I'm waiting for another update when the data is incorrect.The "-t" option specifies the template to use, which is in param03 - "pct:used". Param 04 is the actual data to insert, starting with the date/time in seconds ( i.e. 1196446447), then zero for the "pct" value, then zero for the "used" value. This stuff may not help much, but maybe it will show where the data goes weird - i.e. is hobbitd_rrd being handed bad data, or does it get corrupted later on.That's what I'm hoping. One other thing I noticed is that for the hosts that have bad graphs, but where some graphs are still okay, the good graphs have a gap of data precisely when the bad graphs have another data spike.
-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer
list Greg L Hubbard
You know what -- it almost looks like you are getting a timestamp where another data value is suspected. It could be that the client is not sending data reliably, and the field positions are off by one?
▸
From: Gary Baluha [mailto:user-ae3e15c22de1@xymon.invalid]
Sent: Friday, November 30, 2007 12:31 PM
To: user-ae9b8668bcde@xymon.invalid
Subject: Re: [hobbit] strange graph behavior - random machines &
graphs
On Nov 30, 2007 1:15 PM, Hubbard, Greg L <user-d970b5e56ec9@xymon.invalid>
wrote:
It sounds like you are zeroing in on the problem. Based
on your other post (and this) it seems that the data is getting logged
okay in the RRD, and that data is being faithfully reproduced by the
graphs. The problem is that the data itself has unexpected values. So
whatever is providing that data to the RRD is either faulty, or is in
turn being misled by something else further upstream.
Yeah, I'm fairly confident now that it is the initial data being
fed into the rrd file that is faulty. I'm still not sure what the
initial "entry point" of this bad data is, though, nor why it is
happening. I have a feeling that once I determine where the entry point
is, that will lead me to the "why".
I don't remember where you said that this data was
coming from. I know there can be a problem with "rollovers" when a
signed integer is used as a counter and it grows to the point where the
sign bit flips. This can cause a big jump in a reading if the software
cannot handle the switch from 2,147,483,647 (hex 7FFFFFF) to the next
value (hex 80000000) which flips the sign bit for a signed 32 bit
integer. This has been a problem in the SNMP world for YEARS.
Hrm, that has been something vaguely on my mind. But I haven't
really thought of that as _the_ reason why, since I don't know why there
would be some sort of data rollover. We're talking about load average
and disk space usage graphs that are showing invalid data. I'm also
curious why it would have started all of a sudden, on two separate
machines. But it does seem more and more like something like an integer
rollover, or similar situation.
list Gary Baluha
Hmm, now this is interesting. I have the Hobbit server (Hobbit A, from a previous post) monitoring my work laptop (mostly so I can test out client-side external scripts). I have been taking my laptop home with me this week, and I noticed that the time period while I'm *at* work, the graphs are plotting valid data. However, during the time that I turn my laptop off and bring it home, to the time that I bring my laptop in the next day and power it on, the graphs are showing the same invalid bogus data that the other bad graphs are showing. In other words, the rrd graphs are getting bogus data for a machine that isn't even reporting to the Hobbit server! Interesting, isn't it?
list Gary Baluha
▸
On Nov 30, 2007 2:14 PM, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:
Hmm, now this is interesting. I have the Hobbit server (Hobbit A, from a previous post) monitoring my work laptop (mostly so I can test out client-side external scripts). I have been taking my laptop home with me this week, and I noticed that the time period while I'm *at* work, the graphs are plotting valid data. However, during the time that I turn my laptop off and bring it home, to the time that I bring my laptop in the next day and power it on, the graphs are showing the same invalid bogus data that the other bad graphs are showing. In other words, the rrd graphs are getting bogus data for a machine that isn't even reporting to the Hobbit server! Interesting, isn't it?
I'm definitely on to something with this. I intentionally stopped the
Hobbit client process on one of the machines that has the bad RRD graphs for
about 20 minutes, and then started it back up. Once the client reported the
latest data back, the RRD graph had another spike in it!
The other interesting thing is, the hobbitd-rrd --debug logging (
rrd-status.log) does *not* show any abnormal data. It appears that Hobbit
is logging valid data to "rrdupdate". So the bogus data appears to be
down-stream of this.
So it seems these data spikes *do* correspond to something: they correspond
to a lack of data reported back from the clients. Furthermore, when I do an
rrd dump, I can see the bogus data in the "secondary_value" field:
-----Start of RRD dump-----
<!-- Round Robin Archives --> <rra>
<cf> AVERAGE </cf>
<pdp_per_row> 1 </pdp_per_row> <!-- 300 seconds -->
<params>
<xff> 5.0000000000e-01 </xff>
</params>
<cdp_prep>
<ds>
<primary_value> 2.6110000000e+01 </primary_value>
<secondary_value> 5.1776682516e+170</secondary_value>
<value> 5.1776682516e+170 </value>
<unknown_datapoints> 0 </unknown_datapoints>
</ds>
</cdp_prep>
<database>
<!-- 2007-11-28 15:05:00 EST / 1196280300 -->
<row><v> 5.1776682516e+170 </v></row>
-----SNIP-----
-----End of RRD dump-----
The number 5.1776682516e+170 corresponds to the "517768..." large number
that the GPRINT portion of the rrd graphs are displaying.
Anyone have any ideas of what else to turn logging up on?
list Gary Baluha
I'm almost certain now that this is a problem when Hobbit/rrdtool doesn't receive data when it is expecting it. In short, it seems that when a lack of data occurs, instead of assigning NaN or 0, this huge number is inserted into rrd database instead. I'm still not sure where this number is generated from, though.
list Josh Luthman
Possibly the maximum value for that data entry type? Josh
▸
On 12/3/07, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:I'm almost certain now that this is a problem when Hobbit/rrdtool doesn't receive data when it is expecting it. In short, it seems that when a lack of data occurs, instead of assigning NaN or 0, this huge number is inserted into rrd database instead. I'm still not sure where this number is generated from, though.
-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer
list Gary Baluha
I am now completely convinced that the strange behavior of the graphs is due to some bad data getting inserted into the .rrd database files. The bad data is always the same value: 5.1776682516e+170. That's what the value looks like when you do an rrddump on the .rrd database file. I still have no idea where this value is coming from, but I have at least determined how to fix these graphs. I'm working on a script to do this, but for now, I manually do an rrddump of the file, change all bogus values to NaN (basically, searching for "e+1", since none of the values I trend generally get that large, so I know these entries are just averaged values of correct data and the 5.17... number), and then do an rrdrestore from the modified xml file. It would be nice to determine where this problem is coming from, though.
list Thomas Kern
Could you give a short example of a bogus and a changed (NaN) entry, just in case that is also happening to some of my data files? /Thomas Kern /XXX-XXX-XXXX (O) /XXX-XXX-XXXX (M)
▸
From: Gary Baluha [mailto:user-ae3e15c22de1@xymon.invalid]
Sent: Wednesday, December 05, 2007 11:53 AM
To: user-ae9b8668bcde@xymon.invalid
Subject: Re: [hobbit] strange graph behavior - random machines &
graphs
I am now completely convinced that the strange behavior of the
graphs is due to some bad data getting inserted into the .rrd database
files. The bad data is always the same value: 5.1776682516e+170.
That's what the value looks like when you do an rrddump on the .rrd
database file.
I still have no idea where this value is coming from, but I have
at least determined how to fix these graphs. I'm working on a script to
do this, but for now, I manually do an rrddump of the file, change all
bogus values to NaN (basically, searching for "e+1", since none of the
values I trend generally get that large, so I know these entries are
just averaged values of correct data and the 5.17... number), and then
do an rrdrestore from the modified xml file.
It would be nice to determine where this problem is coming from,
though.
list Gary Baluha
cd hobbit_data_dir/host_machine rrdtool dump clock.rrd > clock.xml I know any number that shows up greater than "e+1nn" is bogus, so I search for "e+1". One of several bogus data lines: <!-- 2007-11-26 19:00:00 EST / 1196121600 --> <row><v> 3.9551632477e+169</v></row> Same line, changed to NaN (repeat for all affected lines): <!-- 2007-11-26 19:00:00 EST / 1196121600 --> <row><v> NaN </v></row> rrdtool restore clock.xml clock.rrd
▸
On Dec 5, 2007 11:57 AM, Kern, Thomas <user-f1ebafb19faf@xymon.invalid> wrote:
Could you give a short example of a bogus and a changed (NaN) entry, just in case that is also happening to some of my data files? /Thomas Kern /XXX-XXX-XXXX (O) /XXX-XXX-XXXX (M) *From:* Gary Baluha [mailto:user-ae3e15c22de1@xymon.invalid] *Sent:* Wednesday, December 05, 2007 11:53 AM *To:* user-ae9b8668bcde@xymon.invalid *Subject:* Re: [hobbit] strange graph behavior - random machines & graphs I am now completely convinced that the strange behavior of the graphs is due to some bad data getting inserted into the .rrd database files. The bad data is always the same value: 5.1776682516e+170. That's what the value looks like when you do an rrddump on the .rrd database file. I still have no idea where this value is coming from, but I have at least determined how to fix these graphs. I'm working on a script to do this, but for now, I manually do an rrddump of the file, change all bogus values to NaN (basically, searching for "e+1", since none of the values I trend generally get that large, so I know these entries are just averaged values of correct data and the 5.17... number), and then do an rrdrestore from the modified xml file. It would be nice to determine where this problem is coming from, though.
list Gary Baluha
I wrote a script to clean up these bogus values. Of course, if there are trend graphs where numbers large enough for NNNe+1NN to be valid, the script will have unexpected results. To run the script, you need to "cd" into the directory with the rrd files to be fixed.
▸
On Dec 5, 2007 2:05 PM, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:
cd hobbit_data_dir/host_machine rrdtool dump clock.rrd > clock.xml I know any number that shows up greater than "e+1nn" is bogus, so I search for "e+1". One of several bogus data lines: <!-- 2007-11-26 19:00:00 EST / 1196121600 --> <row><v> 3.9551632477e+169</v></row> Same line, changed to NaN (repeat for all affected lines): <!-- 2007-11-26 19:00:00 EST / 1196121600 --> <row><v> NaN </v></row> rrdtool restore clock.xml clock.rrd On Dec 5, 2007 11:57 AM, Kern, Thomas <user-f1ebafb19faf@xymon.invalid> wrote:Could you give a short example of a bogus and a changed (NaN) entry, just in case that is also happening to some of my data files? /Thomas Kern /XXX-XXX-XXXX (O) /XXX-XXX-XXXX (M) *From:* Gary Baluha [mailto:user-ae3e15c22de1@xymon.invalid] *Sent:* Wednesday, December 05, 2007 11:53 AM *To:* user-ae9b8668bcde@xymon.invalid *Subject:* Re: [hobbit] strange graph behavior - random machines & graphs I am now completely convinced that the strange behavior of the graphs is due to some bad data getting inserted into the .rrd database files. The bad data is always the same value: 5.1776682516e+170. That's what the value looks like when you do an rrddump on the .rrd database file. I still have no idea where this value is coming from, but I have at least determined how to fix these graphs. I'm working on a script to do this, but for now, I manually do an rrddump of the file, change all bogus values to NaN (basically, searching for "e+1", since none of the values I trend generally get that large, so I know these entries are just averaged values of correct data and the 5.17... number), and then do an rrdrestore from the modified xml file. It would be nice to determine where this problem is coming from, though.
Attachments (1)
list Josh Luthman
Very cool, Gary. Awesome to the max! Thank you very much for sharing your experience and a fix! Just for the record - when using this double check the rrdtool dir and the user:group permissions - not everyone uses those same settings! Again, thanks a lot!
▸
On 12/5/07, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:I wrote a script to clean up these bogus values. Of course, if there are trend graphs where numbers large enough for NNNe+1NN to be valid, the script will have unexpected results. To run the script, you need to "cd" into the directory with the rrd files to be fixed. On Dec 5, 2007 2:05 PM, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:cd hobbit_data_dir/host_machine rrdtool dump clock.rrd > clock.xml I know any number that shows up greater than "e+1nn" is bogus, so I search for "e+1". One of several bogus data lines: <!-- 2007-11-26 19:00:00 EST / 1196121600 --> <row><v> 3.9551632477e+169</v></row> Same line, changed to NaN (repeat for all affected lines): <!-- 2007-11-26 19:00:00 EST / 1196121600 --> <row><v> NaN </v></row> rrdtool restore clock.xml clock.rrd On Dec 5, 2007 11:57 AM, Kern, Thomas <user-f1ebafb19faf@xymon.invalid > wrote:Could you give a short example of a bogus and a changed (NaN) entry, just in case that is also happening to some of my data files? /Thomas Kern /XXX-XXX-XXXX (O) /XXX-XXX-XXXX (M) *From:* Gary Baluha [mailto:user-ae3e15c22de1@xymon.invalid] *Sent:* Wednesday, December 05, 2007 11:53 AM *To:* user-ae9b8668bcde@xymon.invalid *Subject:* Re: [hobbit] strange graph behavior - random machines & graphs I am now completely convinced that the strange behavior of the graphs is due to some bad data getting inserted into the .rrd database files. The bad data is always the same value: 5.1776682516e+170. That's what the value looks like when you do an rrddump on the .rrd database file. I still have no idea where this value is coming from, but I have at least determined how to fix these graphs. I'm working on a script to do this, but for now, I manually do an rrddump of the file, change all bogus values to NaN (basically, searching for "e+1", since none of the values I trend generally get that large, so I know these entries are just averaged values of correct data and the 5.17... number), and then do an rrdrestore from the modified xml file. It would be nice to determine where this problem is coming from, though.
-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer
list Gary Baluha
▸
On Dec 5, 2007 6:01 PM, Josh Luthman <user-4c45a83f15cb@xymon.invalid> wrote:
Very cool, Gary. Awesome to the max! Thank you very much for sharing your experience and a fix! Just for the record - when using this double check the rrdtool dir and the user:group permissions - not everyone uses those same settings!
Yeah, I thought of that after I uploaded the script. It's a simple enough script that people can just modify the appropriate sections of code to suit their environments.
▸
Again, thanks a lot! On 12/5/07, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:I wrote a script to clean up these bogus values. Of course, if there are trend graphs where numbers large enough for NNNe+1NN to be valid, the script will have unexpected results. To run the script, you need to "cd" into the directory with the rrd files to be fixed. On Dec 5, 2007 2:05 PM, Gary Baluha < user-ae3e15c22de1@xymon.invalid> wrote:cd hobbit_data_dir/host_machine rrdtool dump clock.rrd > clock.xml I know any number that shows up greater than "e+1nn" is bogus, so I search for "e+1". One of several bogus data lines: <!-- 2007-11-26 19:00:00 EST / 1196121600 --> <row><v>
3.9551632477e+169 </v></row>
▸
Same line, changed to NaN (repeat for all affected lines): <!-- 2007-11-26 19:00:00 EST / 1196121600 --> <row><v> NaN </v></row> rrdtool restore clock.xml clock.rrd On Dec 5, 2007 11:57 AM, Kern, Thomas < user-f1ebafb19faf@xymon.invalid >
▸
wrote:Could you give a short example of a bogus and a changed (NaN) entry, just in case that is also happening to some of my data files? /Thomas Kern /XXX-XXX-XXXX (O) /XXX-XXX-XXXX (M) *From:* Gary Baluha [mailto:user-ae3e15c22de1@xymon.invalid ] *Sent:* Wednesday, December 05, 2007 11:53 AM *To:* user-ae9b8668bcde@xymon.invalid *Subject:* Re: [hobbit] strange graph behavior - random machines & graphs I am now completely convinced that the strange behavior of the graphs is due to some bad data getting inserted into the .rrd database files. The bad data is always the same value: 5.1776682516e+170. That's what the value looks like when you do an rrddump on the .rrd database file. I still have no idea where this value is coming from, but I have at least determined how to fix these graphs. I'm working on a script to do this, but for now, I manually do an rrddump of the file, change all bogus values to NaN (basically, searching for "e+1", since none of the values I trend generally get that large, so I know these entries are just averaged values of correct data and the 5.17... number), and then do an rrdrestore from the modified xml file. It would be nice to determine where this problem is coming from, though.-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer
list Josh Luthman
You're fine - I just wanted it noted in the mailing list archive =)
▸
On 12/6/07, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:On Dec 5, 2007 6:01 PM, Josh Luthman <user-4c45a83f15cb@xymon.invalid> wrote:Very cool, Gary. Awesome to the max! Thank you very much for sharing your experience and a fix! Just for the record - when using this double check the rrdtool dir and the user:group permissions - not everyone uses those same settings!Yeah, I thought of that after I uploaded the script. It's a simple enough script that people can just modify the appropriate sections of code to suit their environments.Again, thanks a lot! On 12/5/07, Gary Baluha <user-ae3e15c22de1@xymon.invalid > wrote:I wrote a script to clean up these bogus values. Of course, if there are trend graphs where numbers large enough for NNNe+1NN to be valid, the script will have unexpected results. To run the script, you need to "cd" into the directory with the rrd files to be fixed. On Dec 5, 2007 2:05 PM, Gary Baluha < user-ae3e15c22de1@xymon.invalid> wrote:cd hobbit_data_dir/host_machine rrdtool dump clock.rrd > clock.xml I know any number that shows up greater than "e+1nn" is bogus, so I search for "e+1". One of several bogus data lines: <!-- 2007-11-26 19:00:00 EST / 1196121600 --> <row><v> 3.9551632477e+169 </v></row> Same line, changed to NaN (repeat for all affected lines): <!-- 2007-11-26 19:00:00 EST / 1196121600 --> <row><v> NaN </v></row> rrdtool restore clock.xml clock.rrd On Dec 5, 2007 11:57 AM, Kern, Thomas < user-f1ebafb19faf@xymon.invalid > wrote:Could you give a short example of a bogus and a changed (NaN) entry, just in case that is also happening to some of my data files? /Thomas Kern /XXX-XXX-XXXX (O) /XXX-XXX-XXXX (M) *From:* Gary Baluha [mailto:user-ae3e15c22de1@xymon.invalid ] *Sent:* Wednesday, December 05, 2007 11:53 AM *To:* user-ae9b8668bcde@xymon.invalid *Subject:* Re: [hobbit] strange graph behavior - random machines & graphs I am now completely convinced that the strange behavior of the graphs is due to some bad data getting inserted into the .rrd database files. The bad data is always the same value: 5.1776682516e+170. That's what the value looks like when you do an rrddump on the .rrd database file. I still have no idea where this value is coming from, but I have at least determined how to fix these graphs. I'm working on a script to do this, but for now, I manually do an rrddump of the file, change all bogus values to NaN (basically, searching for "e+1", since none of the values I trend generally get that large, so I know these entries are just averaged values of correct data and the 5.17... number), and then do an rrdrestore from the modified xml file. It would be nice to determine where this problem is coming from, though.-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer
-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer
list Gary Baluha
This problem is definitely due to a lack of data. There are two hobbitd_rrd processes that run, as we all know. Why are there two processes, again?
list Greg L Hubbard
One listens to the "data" channel and the other listens to the "status" channel?
▸
From: Gary Baluha [mailto:user-ae3e15c22de1@xymon.invalid]
Sent: Friday, December 07, 2007 2:13 PM
To: user-ae9b8668bcde@xymon.invalid
Subject: Re: [hobbit] strange graph behavior - random machines &
graphs
This problem is definitely due to a lack of data.
There are two hobbitd_rrd processes that run, as we all know.
Why are there two processes, again?
list Gary Baluha
I'm curious, is anyone else having this issue? For reference, I have attached a typical screen shot of one of the broken graphs; I think it's a better representation than an earlier screen shot I provided. If it's some bug in hobbit and/or rrdtool, I would think I'm not the only one with this problem.
Attachments (1)
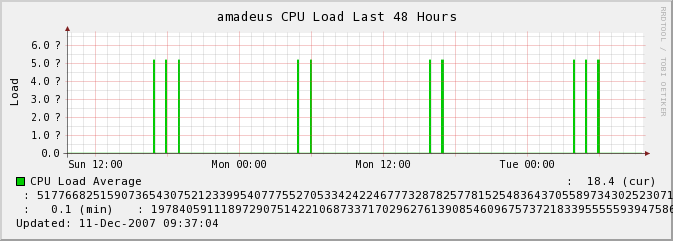 attachment.png
attachment.pnglist Gary Baluha
To try and narrow down the problem some more, I got rid of all the old, unused rrd data files and directories in Hobbit's /data directory, and removed all the bogus data from all of them. Since the problem re-occurred, I can fairly confidently say it has nothing to do with having too many rrd files (hey, you never know).
▸
On Dec 11, 2007 9:42 AM, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:
I'm curious, is anyone else having this issue? For reference, I have attached a typical screen shot of one of the broken graphs; I think it's a better representation than an earlier screen shot I provided. If it's some bug in hobbit and/or rrdtool, I would think I'm not the only one with this problem.
list Galen Johnson
Gary, Are you cross-posting to the rrd lists as well? Someone there may be better able to tell you where to look..or give some idea of something Henrik may need to check in the code. Most of us are rrd consumers only and even fewer see the same issue. I wish I were since I like debugging troublesome issues...much more fun than just clicking "next" when prompted or './configure && make && make install'. =G=
▸
From: Gary Baluha [mailto:user-ae3e15c22de1@xymon.invalid]
Sent: Wednesday, December 12, 2007 10:15 AM
To: user-ae9b8668bcde@xymon.invalid
Subject: Re: [hobbit] strange graph behavior - random machines & graphs
To try and narrow down the problem some more, I got rid of all the old,
unused rrd data files and directories in Hobbit's /data directory, and
removed all the bogus data from all of them. Since the problem
re-occurred, I can fairly confidently say it has nothing to do with
having too many rrd files (hey, you never know).
On Dec 11, 2007 9:42 AM, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:
I'm curious, is anyone else having this issue? For reference, I have
attached a typical screen shot of one of the broken graphs; I think it's
a better representation than an earlier screen shot I provided. If it's
some bug in hobbit and/or rrdtool, I would think I'm not the only one
with this problem.
list Josh Luthman
I think a lot of us are thinking "speak for yourself, Gary" =) I, too, enjoy a good challenge some times...but not when I'm too busy with other tasks - almost all the time =(
▸
On 12/12/07, Galen Johnson <user-87f955643e3d@xymon.invalid> wrote:Gary, Are you cross-posting to the rrd lists as well? Someone there may be better able to tell you where to look..or give some idea of something Henrik may need to check in the code. Most of us are rrd consumers only and even fewer see the same issue. I wish I were since I like debugging troublesome issues…much more fun than just clicking "next" when prompted or './configure && make && make install'. =G= *From:* Gary Baluha [mailto:user-ae3e15c22de1@xymon.invalid] *Sent:* Wednesday, December 12, 2007 10:15 AM *To:* user-ae9b8668bcde@xymon.invalid *Subject:* Re: [hobbit] strange graph behavior - random machines & graphs To try and narrow down the problem some more, I got rid of all the old, unused rrd data files and directories in Hobbit's /data directory, and removed all the bogus data from all of them. Since the problem re-occurred, I can fairly confidently say it has nothing to do with having too many rrd files (hey, you never know). On Dec 11, 2007 9:42 AM, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote: I'm curious, is anyone else having this issue? For reference, I have attached a typical screen shot of one of the broken graphs; I think it's a better representation than an earlier screen shot I provided. If it's some bug in hobbit and/or rrdtool, I would think I'm not the only one with this problem.
-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer
list Galen Johnson
No, no...you misunderstood...I'm not saying user-31c7974c1875@xymon.invalid asking if he was pursuing that path as well. =G=
▸
From: Josh Luthman [mailto:user-4c45a83f15cb@xymon.invalid]
Sent: Wednesday, December 12, 2007 10:29 AM
To: user-ae9b8668bcde@xymon.invalid
Subject: Re: [hobbit] strange graph behavior - random machines & graphs
I think a lot of us are thinking "speak for yourself, Gary" =)
I, too, enjoy a good challenge some times...but not when I'm too busy
with other tasks - almost all the time =(
On 12/12/07, Galen Johnson <user-87f955643e3d@xymon.invalid> wrote:
Gary,
Are you cross-posting to the rrd lists as well? Someone there may be
better able to tell you where to look..or give some idea of something
Henrik may need to check in the code. Most of us are rrd consumers only
and even fewer see the same issue. I wish I were since I like debugging
troublesome issues...much more fun than just clicking "next" when
prompted or './configure && make && make install'.
=G=
From: Gary Baluha [mailto:user-ae3e15c22de1@xymon.invalid]
Sent: Wednesday, December 12, 2007 10:15 AM
To: user-ae9b8668bcde@xymon.invalid
Subject: Re: [hobbit] strange graph behavior - random machines & graphs
To try and narrow down the problem some more, I got rid of all the old,
unused rrd data files and directories in Hobbit's /data directory, and
removed all the bogus data from all of them. Since the problem
re-occurred, I can fairly confidently say it has nothing to do with
having too many rrd files (hey, you never know).
On Dec 11, 2007 9:42 AM, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:
I'm curious, is anyone else having this issue? For reference, I have
attached a typical screen shot of one of the broken graphs; I think it's
a better representation than an earlier screen shot I provided. If it's
some bug in hobbit and/or rrdtool, I would think I'm not the only one
with this problem.
--
Josh Luthman
Office: XXX-XXX-XXXX
Direct: XXX-XXX-XXXX
XXXX Wayne St
Suite XXXX
Troy, OH XXXXX
Those who don't understand UNIX are condemned to reinvent it, poorly.
--- Henry Spencer
list Josh Luthman
I see. So from what I can tell we're up to the developer or an aid to fix this issue? Gary did provide a workaround, still... Josh On 12/12/07, Galen Johnson <user-87f955643e3d@xymon.invalid> wrote:
No, no…you misunderstood…I'm not saying that at all…just asking if he was
▸
pursuing that path as well.
=G=
*From:* Josh Luthman [mailto:user-4c45a83f15cb@xymon.invalid]
*Sent:* Wednesday, December 12, 2007 10:29 AM
*To:* user-ae9b8668bcde@xymon.invalid
*Subject:* Re: [hobbit] strange graph behavior - random machines & graphs
I think a lot of us are thinking "speak for yourself, Gary" =)
I, too, enjoy a good challenge some times...but not when I'm too busy with
other tasks - almost all the time =(
On 12/12/07, *Galen Johnson* <user-87f955643e3d@xymon.invalid> wrote:
Gary,
Are you cross-posting to the rrd lists as well? Someone there may be
better able to tell you where to look..or give some idea of something Henrik
may need to check in the code. Most of us are rrd consumers only and even
fewer see the same issue. I wish I were since I like debugging troublesome
issues…much more fun than just clicking "next" when prompted or './configure
&& make && make install'.
=G=
*From:* Gary Baluha [mailto:user-ae3e15c22de1@xymon.invalid]
*Sent:* Wednesday, December 12, 2007 10:15 AM
*To:* user-ae9b8668bcde@xymon.invalid
*Subject:* Re: [hobbit] strange graph behavior - random machines & graphs
To try and narrow down the problem some more, I got rid of all the old,
unused rrd data files and directories in Hobbit's /data directory, and
removed all the bogus data from all of them. Since the problem re-occurred,
I can fairly confidently say it has nothing to do with having too many rrd
files (hey, you never know).
On Dec 11, 2007 9:42 AM, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:
I'm curious, is anyone else having this issue? For reference, I have
attached a typical screen shot of one of the broken graphs; I think it's a
better representation than an earlier screen shot I provided. If it's some
bug in hobbit and/or rrdtool, I would think I'm not the only one with this
problem.
--
Josh Luthman
Office: XXX-XXX-XXXX
Direct: XXX-XXX-XXXX
XXXX Wayne St
Suite XXXX
Troy, OH XXXXX
Those who don't understand UNIX are condemned to reinvent it, poorly.
--- Henry Spencer
-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer
list Gary Baluha
▸
No, no…you misunderstood…I'm not saying that at all…just asking if he was pursuing that path as well.
Yes, I have posted a thread on the RRD forum (though I'm not doing a full cross-posting). I haven't gotten any responses back yet, and besides I'm not convinced it is a problem with RRD (or for that matter, Hobbit). My main reason for updating this thread in the hobbit list is because much of it is Hobbit related (even if Hobbit itself isn't the cause).
▸
=G= *From:* Josh Luthman [mailto:user-4c45a83f15cb@xymon.invalid] *Sent:* Wednesday, December 12, 2007 10:29 AM *To:* user-ae9b8668bcde@xymon.invalid *Subject:* Re: [hobbit] strange graph behavior - random machines & graphs I think a lot of us are thinking "speak for yourself, Gary" =) I, too, enjoy a good challenge some times...but not when I'm too busy with other tasks - almost all the time =(
Heheh, since I seem to be the only one with this problem so far (or at least, the only one to post about it), I'm doing most of the responding to my own thread. Oh well, I've learned quite a bit about how Hobbit and RRD both work. This is certainly a good challenge, since so many factors are involved in this problem. Unfortunately for me, we have people here that might try to represent this problem as a reason to get off Hobbit and use an inferior pay-ware monitoring solution. Thankfully I figured out a work-around, so I'm hoping that will buy me enough time to finally figure this one out. ...And hopefully in the mean time, I don't cause too much irrelevant noise on this mailing list, responding to my own problem ;-)
▸
On 12/12/07, *Galen Johnson* <user-87f955643e3d@xymon.invalid> wrote: Gary, Are you cross-posting to the rrd lists as well? Someone there may be better able to tell you where to look..or give some idea of something Henrik may need to check in the code. Most of us are rrd consumers only and even fewer see the same issue. I wish I were since I like debugging troublesome issues…much more fun than just clicking "next" when prompted or './configure && make && make install'. =G= *From:* Gary Baluha [mailto:user-ae3e15c22de1@xymon.invalid] *Sent:* Wednesday, December 12, 2007 10:15 AM *To:* user-ae9b8668bcde@xymon.invalid *Subject:* Re: [hobbit] strange graph behavior - random machines & graphs To try and narrow down the problem some more, I got rid of all the old, unused rrd data files and directories in Hobbit's /data directory, and removed all the bogus data from all of them. Since the problem re-occurred, I can fairly confidently say it has nothing to do with having too many rrd files (hey, you never know). On Dec 11, 2007 9:42 AM, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote: I'm curious, is anyone else having this issue? For reference, I have attached a typical screen shot of one of the broken graphs; I think it's a better representation than an earlier screen shot I provided. If it's some bug in hobbit and/or rrdtool, I would think I'm not the only one with this problem. -- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer
list Galen Johnson
We appreciate that...too many list users forget to reply with their fix (this is a global phenomena) and the debugging steps they did so the next guy that goes looking is left wondering.
▸
=G=
From: Gary Baluha [mailto:user-ae3e15c22de1@xymon.invalid]
Sent: Wednesday, December 12, 2007 1:46 PM
To: user-ae9b8668bcde@xymon.invalid
Subject: Re: [hobbit] strange graph behavior - random machines & graphs
No, no...you misunderstood...I'm not saying user-31c7974c1875@xymon.invalid
asking if he was pursuing that path as well.
Yes, I have posted a thread on the RRD forum (though I'm not doing a
full cross-posting). I haven't gotten any responses back yet, and
besides I'm not convinced it is a problem with RRD (or for that matter,
Hobbit).
My main reason for updating this thread in the hobbit list is because
much of it is Hobbit related (even if Hobbit itself isn't the cause).
=G=
From: Josh Luthman [mailto:user-4c45a83f15cb@xymon.invalid]
Sent: Wednesday, December 12, 2007 10:29 AM
To: user-ae9b8668bcde@xymon.invalid
Subject: Re: [hobbit] strange graph behavior - random machines &
graphs
I think a lot of us are thinking "speak for yourself, Gary" =)
I, too, enjoy a good challenge some times...but not when I'm too
busy with other tasks - almost all the time =(
Heheh, since I seem to be the only one with this problem so far (or at
least, the only one to post about it), I'm doing most of the responding
to my own thread. Oh well, I've learned quite a bit about how Hobbit
and RRD both work.
This is certainly a good challenge, since so many factors are involved
in this problem. Unfortunately for me, we have people here that might
try to represent this problem as a reason to get off Hobbit and use an
inferior pay-ware monitoring solution. Thankfully I figured out a
work-around, so I'm hoping that will buy me enough time to finally
figure this one out.
...And hopefully in the mean time, I don't cause too much irrelevant
noise on this mailing list, responding to my own problem ;-)
On 12/12/07, Galen Johnson <user-87f955643e3d@xymon.invalid> wrote:
Gary,
Are you cross-posting to the rrd lists as well? Someone there
may be better able to tell you where to look..or give some idea of
something Henrik may need to check in the code. Most of us are rrd
consumers only and even fewer see the same issue. I wish I were since I
like debugging troublesome issues...much more fun than just clicking
"next" when prompted or './configure && make && make install'.
=G=
From: Gary Baluha [mailto:user-ae3e15c22de1@xymon.invalid]
Sent: Wednesday, December 12, 2007 10:15 AM
To: user-ae9b8668bcde@xymon.invalid
Subject: Re: [hobbit] strange graph behavior - random machines &
graphs
To try and narrow down the problem some more, I got rid of all
the old, unused rrd data files and directories in Hobbit's /data
directory, and removed all the bogus data from all of them. Since the
problem re-occurred, I can fairly confidently say it has nothing to do
with having too many rrd files (hey, you never know).
On Dec 11, 2007 9:42 AM, Gary Baluha <user-ae3e15c22de1@xymon.invalid>
wrote:
I'm curious, is anyone else having this issue? For reference, I
have attached a typical screen shot of one of the broken graphs; I think
it's a better representation than an earlier screen shot I provided. If
it's some bug in hobbit and/or rrdtool, I would think I'm not the only
one with this problem.
--
Josh Luthman
Office: XXX-XXX-XXXX
Direct: XXX-XXX-XXXX
XXXX Wayne St
Suite XXXX
Troy, OH XXXXX
Those who don't understand UNIX are condemned to reinvent it,
poorly.
--- Henry Spencer
list Josh Luthman
I'm with Galen. Thanks for the documentation =)
▸
On 12/12/07, Galen Johnson <user-87f955643e3d@xymon.invalid> wrote:We appreciate that…too many list users forget to reply with their fix (this is a global phenomena) and the debugging steps they did so the next guy that goes looking is left wondering. =G= *From:* Gary Baluha [mailto:user-ae3e15c22de1@xymon.invalid] *Sent:* Wednesday, December 12, 2007 1:46 PM *To:* user-ae9b8668bcde@xymon.invalid *Subject:* Re: [hobbit] strange graph behavior - random machines & graphs No, no…you misunderstood…I'm not saying that at all…just asking if he was pursuing that path as well. Yes, I have posted a thread on the RRD forum (though I'm not doing a full cross-posting). I haven't gotten any responses back yet, and besides I'm not convinced it is a problem with RRD (or for that matter, Hobbit). My main reason for updating this thread in the hobbit list is because much of it is Hobbit related (even if Hobbit itself isn't the cause). =G= *From:* Josh Luthman [mailto:user-4c45a83f15cb@xymon.invalid] *Sent:* Wednesday, December 12, 2007 10:29 AM *To:* user-ae9b8668bcde@xymon.invalid *Subject:* Re: [hobbit] strange graph behavior - random machines & graphs I think a lot of us are thinking "speak for yourself, Gary" =) I, too, enjoy a good challenge some times...but not when I'm too busy with other tasks - almost all the time =( Heheh, since I seem to be the only one with this problem so far (or at least, the only one to post about it), I'm doing most of the responding to my own thread. Oh well, I've learned quite a bit about how Hobbit and RRD both work. This is certainly a good challenge, since so many factors are involved in this problem. Unfortunately for me, we have people here that might try to represent this problem as a reason to get off Hobbit and use an inferior pay-ware monitoring solution. Thankfully I figured out a work-around, so I'm hoping that will buy me enough time to finally figure this one out. ...And hopefully in the mean time, I don't cause too much irrelevant noise on this mailing list, responding to my own problem ;-) On 12/12/07, *Galen Johnson* <user-87f955643e3d@xymon.invalid> wrote: Gary, Are you cross-posting to the rrd lists as well? Someone there may be better able to tell you where to look..or give some idea of something Henrik may need to check in the code. Most of us are rrd consumers only and even fewer see the same issue. I wish I were since I like debugging troublesome issues…much more fun than just clicking "next" when prompted or './configure && make && make install'. =G= *From:* Gary Baluha [mailto:user-ae3e15c22de1@xymon.invalid] *Sent:* Wednesday, December 12, 2007 10:15 AM *To:* user-ae9b8668bcde@xymon.invalid *Subject:* Re: [hobbit] strange graph behavior - random machines & graphs To try and narrow down the problem some more, I got rid of all the old, unused rrd data files and directories in Hobbit's /data directory, and removed all the bogus data from all of them. Since the problem re-occurred, I can fairly confidently say it has nothing to do with having too many rrd files (hey, you never know). On Dec 11, 2007 9:42 AM, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote: I'm curious, is anyone else having this issue? For reference, I have attached a typical screen shot of one of the broken graphs; I think it's a better representation than an earlier screen shot I provided. If it's some bug in hobbit and/or rrdtool, I would think I'm not the only one with this problem. -- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer
-- Josh Luthman Office: XXX-XXX-XXXX Direct: XXX-XXX-XXXX XXXX Wayne St Suite XXXX Troy, OH XXXXX Those who don't understand UNIX are condemned to reinvent it, poorly. --- Henry Spencer
list Gary Baluha
It's interesting that it seems the CPU Load and Users and Processes graphs are the graphs that are most likely to have this strange corruption. I have also seen it on a few Disk graphs, but not nearly as many as the other two graphs. Interestingly, the CPU Utilization, Network I/O, and TCP Connection Times graphs have _never_ had this corruption. I'd also like to say the Memory Utilization graph hasn't had this issue either, though I can't recall with complete certainty that that is the case. I wonder what the main difference between the 3 graphs that do have the issue is, and the 3 (possibly 4) graphs that have never exhibited this issue. There must be some physical difference, as I can't imagine it is all do purely to luck...
list Gary Baluha
I thought I'd revisit this issue again. A new thought has occurred to me... Where does Hobbit generate the RRD files? I wonder what parameters Hobbit is using to pass to rrdtool, and if something there might be acting funny with some of the data I'm providing to that Hobbit module.
▸
On Wed, Dec 19, 2007 at 10:59 AM, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:
It's interesting that it seems the CPU Load and Users and Processes graphs are the graphs that are most likely to have this strange corruption. I have also seen it on a few Disk graphs, but not nearly as many as the other two graphs. Interestingly, the CPU Utilization, Network I/O, and TCP Connection Times graphs have _never_ had this corruption. I'd also like to say the Memory Utilization graph hasn't had this issue either, though I can't recall with complete certainty that that is the case. I wonder what the main difference between the 3 graphs that do have the issue is, and the 3 (possibly 4) graphs that have never exhibited this issue. There must be some physical difference, as I can't imagine it is all
due purely to luck...
list Greg L Hubbard
If you look through the source, the RRD support modules are easy to spot. If you are using custom graphs, then you need to review the ncv method, or the "roll your own" method. But, since "garbage in -> garbage out" you might be on the right path.
▸
GLH
From: Gary Baluha [mailto:user-ae3e15c22de1@xymon.invalid]
Sent: Monday, April 07, 2008 1:15 PM
To: user-ae9b8668bcde@xymon.invalid
Subject: Re: [hobbit] strange graph behavior - random machines &
graphs
I thought I'd revisit this issue again. A new thought has
occurred to me... Where does Hobbit generate the RRD files? I wonder
what parameters Hobbit is using to pass to rrdtool, and if something
there might be acting funny with some of the data I'm providing to that
Hobbit module.
On Wed, Dec 19, 2007 at 10:59 AM, Gary Baluha
<user-ae3e15c22de1@xymon.invalid> wrote:
It's interesting that it seems the CPU Load and Users
and Processes graphs are the graphs that are most likely to have this
strange corruption. I have also seen it on a few Disk graphs, but not
nearly as many as the other two graphs. Interestingly, the CPU
Utilization, Network I/O, and TCP Connection Times graphs have _never_
had this corruption. I'd also like to say the Memory Utilization graph
hasn't had this issue either, though I can't recall with complete
certainty that that is the case.
I wonder what the main difference between the 3 graphs
that do have the issue is, and the 3 (possibly 4) graphs that have never
exhibited this issue. There must be some physical difference, as I
can't imagine it is all due purely to luck...
list Gary Baluha
In my case, it seems the "garbage" that is going into the graphs is caused by a lack of data, rather than actual bad data. I'm specifically wondering if there's some time interval mix-up that is causing the issue. If anyone would like to see a current example of one of the graphs with bad data, I'll gladly provide a screenshot. On Mon, Apr 7, 2008 at 2:27 PM, Hubbard, Greg L <user-d970b5e56ec9@xymon.invalid>
▸
wrote:
If you look through the source, the RRD support modules are easy to spot. If you are using custom graphs, then you need to review the ncv method, or the "roll your own" method. But, since "garbage in -> garbage out" you might be on the right path. GLH *From:* Gary Baluha [mailto:user-ae3e15c22de1@xymon.invalid] *Sent:* Monday, April 07, 2008 1:15 PM *To:* user-ae9b8668bcde@xymon.invalid *Subject:* Re: [hobbit] strange graph behavior - random machines & graphs I thought I'd revisit this issue again. A new thought has occurred to me... Where does Hobbit generate the RRD files? I wonder what parameters Hobbit is using to pass to rrdtool, and if something there might be acting funny with some of the data I'm providing to that Hobbit module. On Wed, Dec 19, 2007 at 10:59 AM, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:It's interesting that it seems the CPU Load and Users and Processes graphs are the graphs that are most likely to have this strange corruption. I have also seen it on a few Disk graphs, but not nearly as many as the other two graphs. Interestingly, the CPU Utilization, Network I/O, and TCP Connection Times graphs have _never_ had this corruption. I'd also like to say the Memory Utilization graph hasn't had this issue either, though I can't recall with complete certainty that that is the case. I wonder what the main difference between the 3 graphs that do have the issue is, and the 3 (possibly 4) graphs that have never exhibited this issue. There must be some physical difference, as I can't imagine it is all due purely to luck...
list Gary Baluha
Oh, and I'm using the NCV module.
▸
On Mon, Apr 7, 2008 at 2:35 PM, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:
In my case, it seems the "garbage" that is going into the graphs is caused by a lack of data, rather than actual bad data. I'm specifically wondering if there's some time interval mix-up that is causing the issue. If anyone would like to see a current example of one of the graphs with bad data, I'll gladly provide a screenshot. On Mon, Apr 7, 2008 at 2:27 PM, Hubbard, Greg L <user-d970b5e56ec9@xymon.invalid> wrote:If you look through the source, the RRD support modules are easy to spot. If you are using custom graphs, then you need to review the ncv method, or the "roll your own" method. But, since "garbage in -> garbage out" you might be on the right path. GLH *From:* Gary Baluha [mailto:user-ae3e15c22de1@xymon.invalid] *Sent:* Monday, April 07, 2008 1:15 PM *To:* user-ae9b8668bcde@xymon.invalid *Subject:* Re: [hobbit] strange graph behavior - random machines & graphs I thought I'd revisit this issue again. A new thought has occurred to me... Where does Hobbit generate the RRD files? I wonder what parameters Hobbit is using to pass to rrdtool, and if something there might be acting funny with some of the data I'm providing to that Hobbit module. On Wed, Dec 19, 2007 at 10:59 AM, Gary Baluha <user-ae3e15c22de1@xymon.invalid> wrote:It's interesting that it seems the CPU Load and Users and Processes graphs are the graphs that are most likely to have this strange corruption. I have also seen it on a few Disk graphs, but not nearly as many as the other two graphs. Interestingly, the CPU Utilization, Network I/O, and TCP Connection Times graphs have _never_ had this corruption. I'd also like to say the Memory Utilization graph hasn't had this issue either, though I can't recall with complete certainty that that is the case. I wonder what the main difference between the 3 graphs that do have the issue is, and the 3 (possibly 4) graphs that have never exhibited this issue. There must be some physical difference, as I can't imagine it is all due purely to luck...